Project: Uncertainty Visualization for Neural Radiance Fields
Description
View synthesis and 3D reconstruction are complex fundamental problems in computer vision. Although several traditional neural networks for 3D reconstruction have been proposed, they typically cannot represent the high frequency details existing in these signals. Neural Radiance Fields (NeRF) [1] is a new emerging deep learning technique for view synthesis and 3D reconstruction. NeRFs are able to represent one scene as a high frequency signal in a multilayer perceptron (MLP). Given multiple images from different camera poses, the model learns a 3D representation. New 2D training views can be obtained from the 3D representation, which are compared to the original 2D training views to optimize the model.
The application of these networks for machine learning developers in practical scenarios, however, is still a challenge. The deep neural networks can take hours to days to converge. They can also lead to degenerate solutions, especially when training with limited views [2]. For example, the 3D representation may be degenerate and noisy, while the 2D validation views are correct. Naively training multiple networks with different depths and widths is too time-consuming and may not lead to converging solutions. Another limitation of these models is the black-box nature of these models.
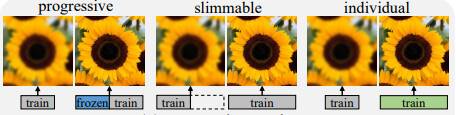
One example of an approach to overcome these limitations are Streamable Neural Fields [3]. A single NeRF model (MLP) is separated into trainable sub-networks of various widths. These sub-networks represent different qualities and parts of the signals. Advantages of using these sub-networks can be modularity, interpretability, consistency and training time.
In this project, we want to take the first steps in understanding the inner workings of NeRF models using Visual Analytics techniques. We would like to progressively visualize the learned signals, e.g. 2D and 3D. Another approach would be to investigate the effects of the Streamable Neural Fields sub-networks on the networks, e.g. on the consistency of the results during training time.
We expect you to have programming and machine learning fundamentals, as well as a basic understanding of visualization.
[1] Mildenhall, B., Srinivasan, P. P., Tancik, M., Barron, J. T., Ramamoorthi, R., & Ng, R. (2021). Nerf: Representing scenes as neural radiance fields for view synthesis. Communications of the ACM, 65(1), 99-106.
[2] Kim, M., Seo, S., & Han, B. (2022). InfoNeRF: Ray Entropy Minimization for Few-Shot Neural Volume Rendering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (pp. 12912-12921).
[3] Cho, J., Nam, S., Rho, D., Ko, J. H., & Park, E. (2022). Streamable neural fields. arXiv preprint arXiv:2207.09663.
Details
- Student
-
TCThiam Wai Chua
- Supervisor
-
 Anna Vilanova
Anna Vilanova
- Secondary supervisor
-
NMNicola Pezzotti, Kirsten Maas