Project: Visual analytics & explainable AI for deep image-to-image translation models
Description
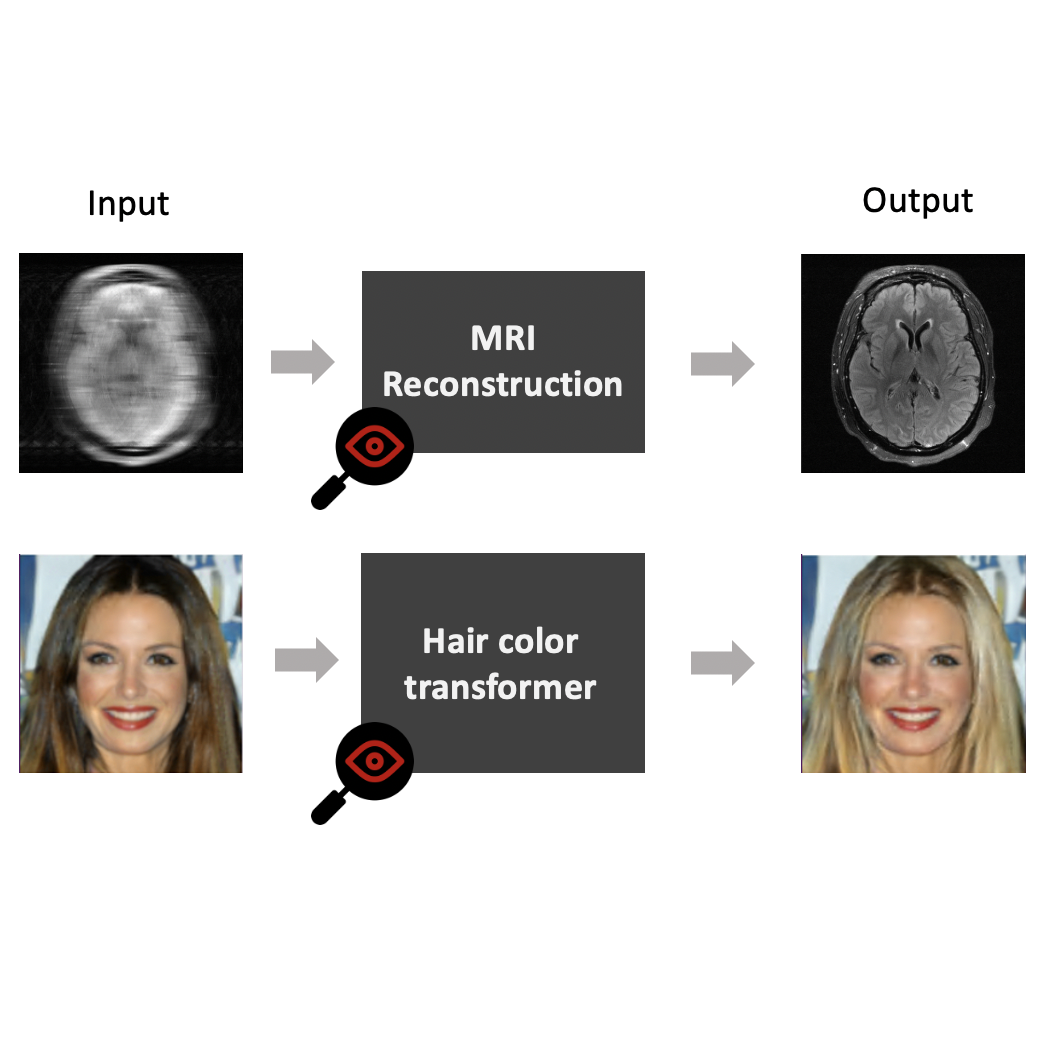
The focus of existing VA systems for explainable DL models has primarily been on classification, which does not exhibit the complexities of image-to-image translation problems. Image-to-image translation models involve transforming data from one form to another, i.e., the input and outputs are high dimensional images. For example, changing facial expressions, denoising, medical image formation, or image synthesis via GANs or diffusion models.
The complexity of understanding image-to-image translation models stems from several factors. Firstly, there's a lack of clear and interpretable data grouping, as these problems typically lack distinct classes for grouping instances. Additionally, the outputs of these models are high-dimensional, with individual pixels within an instance capable of exhibiting distinct behaviors and possessing unique sensitivity maps concerning the input data.Studying and summarizing this information is challenging.
We would like to develop VA and XAI methods to support the understanding of such minimally explored image-to-image translation models. We can define projects within the above scope based on the student’s interest.
Please reach out if you are interested in working in this area or want to know more.
Relevant Literature:
[1] Prasad, Vidya, et al. "The Transform-and-Perform framework: Explainable deep learning beyond classification." IEEE Transactions on Visualization and Computer Graphics (2022).
[2] Prasad, Vidya, et al. "ProactiV: Studying deep learning model behavior under input transformations." IEEE Transactions on Visualization and Computer Graphics (2023).
Details
- Student
-
TPThis was a generic project
- Supervisor
-
 Anna Vilanova
Anna Vilanova
- Secondary supervisor
-
 Vidya Prasad
Vidya Prasad