back to list
Project: On Duplicating Data Points to Reduce the Hubness Impact on Dimensionality Reduction Layouts
Description
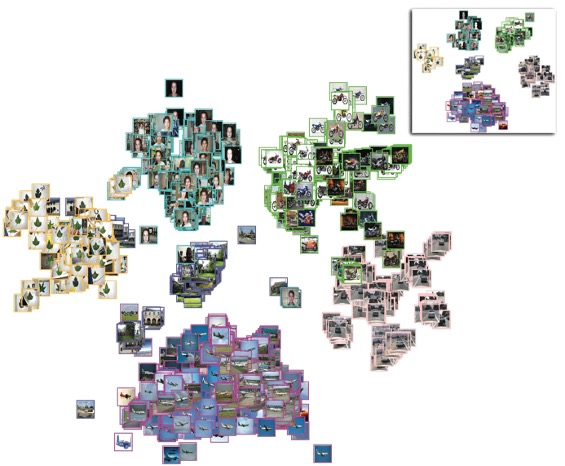
In high-dimensional spaces, one intriguing property is that some data instances are among the k nearest neighbors of most (or all) other instances. This effect is known as data hubness, and the general effect is connecting unrelated manifolds or neighborhoods. While hubness reduction is well-studied for classification and clustering, it is still neglected for dimensionality reduction, and most solutions focus on transforming or distorting the original data to reduce hubness before processing.
This project aims to study how hubness affects dimensionality reduction and proposes a solution where the produced layout and not the data is adapted by duplicating data points to handle situations where unrelated neighborhoods are connected.
Details
- Supervisor
-
 Fernando Paulovich
Fernando Paulovich
- Interested?
- Get in contact