back to list
Project: Visualizing Learned Concepts in Large Language Models
Description
Large Language Models (LLMs) have become a central component of modern AI systems. Despite their impressive performance, they remain largely opaque: understanding what they learn and how they represent meaning is still an open challenge.
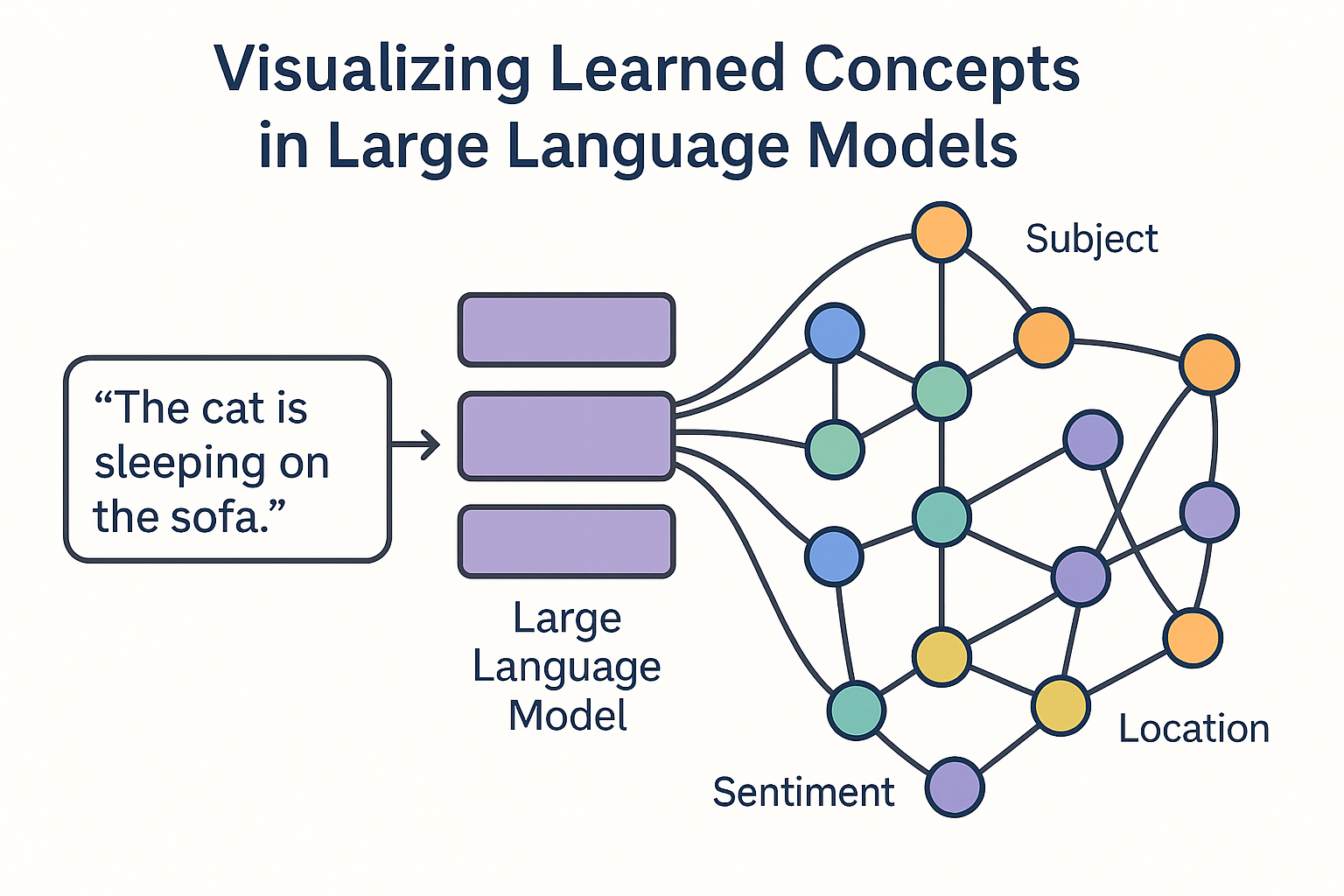
Most existing interpretability techniques visualize low-level model components, such as attention weights or neuron activations. While informative, these views do not align well with how humans reason about language and knowledge. LLMs appear to learn distributed, abstract concepts—such as semantic roles, sentiment, topic structure, or reasoning patterns—that are not localized in individual weights.
This project explores concept-level visualization of LLMs. Instead of focusing on weights or single neurons, the goal is to identify, extract, and visually represent learned concepts and their relationships across layers, prompts, and contexts. The outcome is a visual analytics system that helps users reason about the concepts an LLM has learned and how they evolve internally.
Background
LLMs are typically analyzed using techniques such as:
- Attention visualization
- Feature attribution and saliency maps
However, these methods often produce fragmented or token-level explanations. Recent research suggests that higher-level abstractions emerge in the latent space of transformer models, motivating a shift from parameter-centric to concept-centric interpretability.
Visualization offers a natural medium for bridging the gap between mathematical representations and human understanding.
Objectives
The main objectives of this project are:
- Define and operationalize the notion of a learned concept in LLMs
- Extract concept representations from internal model states.
- Design visual encodings for exploring abstract concepts.
- Enable inspection of concept evolution across model layers.
- Support comparison between prompts, tasks, or models.
Challenges
Key challenges include:
- Learned concepts are distributed and abstract, not explicitly defined.
- Concept boundaries are often fuzzy and overlapping.
- Visualizing high-dimensional, evolving latent spaces.
- Avoiding misleading or over-interpreted explanations.
References
- Daking Rai, Yilun Zhou, Shi Feng, Abulhair Saparov, Ziyu Yao: A Practical Review of Mechanistic Interpretability for Transformer-Based Language Models. CoRR abs/2407.02646 (2024)
Jesse Vig. Visualizing Attention in Transformer-Based Language Representation Models. https://arxiv.org/abs/1904.02679
Detailed description
View PDFDetails
- Supervisor
-
 Fernando Paulovich
Fernando Paulovich
- Interested?
- Get in contact