Project: Visual analytics for deep learning model Interpretation in video turnaround process analysis at Schiphol
Description
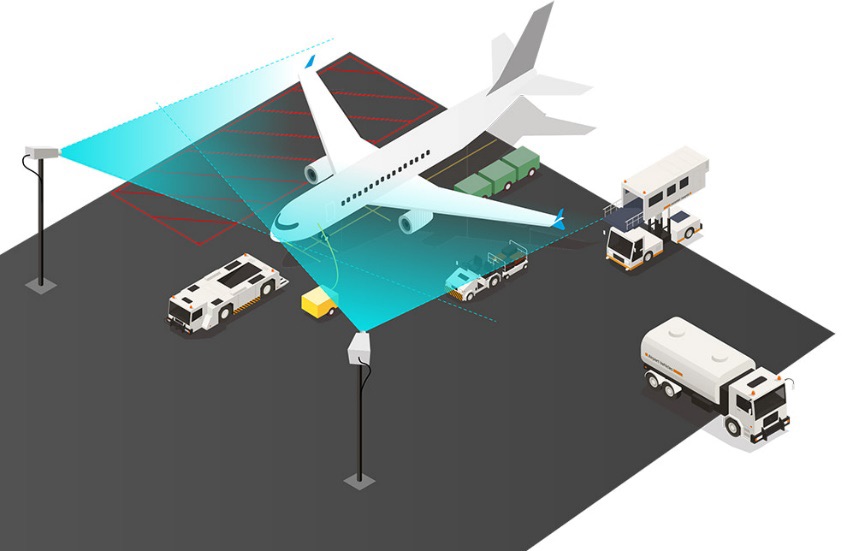
The turnaround process is a series of tasks that need to be executed to prepare a parked aircraft for a new flight (e.g. fueling or loading baggage). The efficient execution of such tasks is necessary to guarantee that most flights will depart on time. Today, the turnaround process is a black box in many airports. To solve the black box problem, the Royal Schiphol Group has developed a technology that uses Deep Learning (DL) to detect in real-time relevant turnaround-related tasks by using images from cameras that are located at the aircraft ramps. This information is used to create performance analytics about the turnaround process and identify potential improvement actions. Another usage is to trigger real-time alerts to spark actions when a flight is at risk of a delay. With this technology, Royal Schiphol Group is expecting to improve its on-time performance making traveling a better experience for their customers.
DL models achieve state-of-the-art performance in tasks such as image or video (also called action recognition) classification. However, because DL models capture complex pixel correlations, the model's prediction interpretability becomes challenging (in contrast to simpler but worst performing models such as logistic regression). DL model prediction interpretability is a fundamental aspect not only to debug the model (e.g., spot spurious correlations), but also to decide what is the best way to improve its performance (e.g., increase the image input size or label more data of challenging classes). Other promising applications can be weak object localization to count and track objects, and automatically identify regions of interest (e.g., passenger doors).
Visual analytics (VA) is a research field that combines machine learning/data analysis with visualization and interaction to enhance the human knowledge and understanding. VA for model interpretation is an active field of research and a promising direction to aid the interpretability of DL models.
The main goal of the project is to design and implement a VA framework focusing on:
- Model prediction interpretation
- Identify the most common error sources
- Provide information for recommendations to improve the model performance
There are a plethora of algorithms that show promising results for model prediction interpretation of images. However, the work done for video prediction interpretation is quite limited. We are interested to explore the VA capabilities and alternatives to interpret video prediction models reliably.
(Some) DL Model Prediction Explainability References:
- http://visualization.tudelft.nl/Publications-new/2018/PHVLEV18/paper216.pdf
- https://arxiv.org/abs/1608.00507
- https://arxiv.org/abs/1910.08485
- https://arxiv.org/abs/1312.6034
- https://openaccess.thecvf.com/content_iccv_2017/html/Selvaraju_Grad-CAM_Visual_Explanations_ICCV_2017_paper.html
- https://arxiv.org/abs/1412.6806
- https://link.springer.com/chapter/10.1007%2F978-3-319-10590-1_53
Details
- Student
-
AVAlina Vorobiova
- Supervisor
-
 Anna Vilanova
Anna Vilanova
- Secondary supervisor
-
SPSantiago Ruiz Zapat, Floris Hoogenboom, Vidya Prasad
- External location
- Royal Schiphol Group
- Link
- Thesis